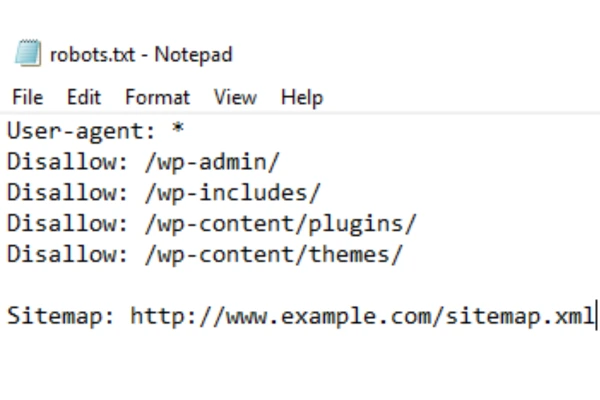
What is Robots txt File?
Robots txt file is a file that implements Robots Exclusion Protocol or REP.
It provides security to the website by putting certain kinds of restrictions over the Search Engines’ Crawlers.
This File provides directions to Search Engines like Google, Yahoo, Bing etc. It tells them which part of the website they are allowed to crawl and grab the information
This file basically contains commands including the words “Allowing” and “Disallowing”. It is generally used to protect the website from unusual requests and prevent the site from overloading.
This is not for keeping your page out of Google. For keeping the web pages off Google, one should noindex directives or should protect the web page with the help of a password.
Robots.txt file is the most important. It is because Google usually picks up the important pages and may automatically rank them without being aware of the page’s duplicity version or it might not be important.
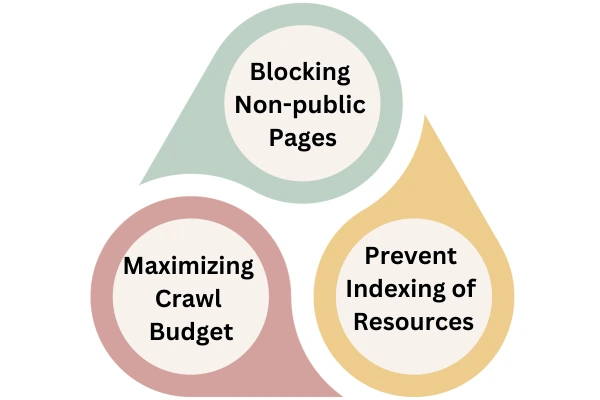
Once the pages get indexed, you cannot switch it back. There are 3 main reasons why we need this file. These are discussed below:-
- Blocking Non-public Pages
- Maximizing Crawl Budget
- Prevent Indexing of Resources
Why Robots.txt File?
1. Blocking Non-public Pages :- There are many pages on which a developer does not want random people to land upon. It may be a login page or any other page.
This file is helpful in such a situation to prevent such pages from indexing.
2. Maximizing Crawl Budget :- Sometimes it is difficult to get all the pages indexed, which raises crawl budget problems.
Crawl Budget is the no. of pages that Googlebot indexes. To prevent this, one should get the important pages indexed first.
Robots.txt file blocks the unimportant pages and lets the Googlebot Crawler crawl important pages first, and index them.
3. Prevent Indexing of Resources :- Robots file help to prevent pages to be indexed by using some meta directives but it doesn’t works on some specific things.
It doesn’t work well on multimedia like images and pdfs, and that’s the place where you need robots file.
It tells the crawlers not to crawl some specific pages. Through Google Search Console, you can find out the no. of indexed pages.
If it shows the exact no. of pages you want, there is no worry but if the actual no. of indexed pages are higher than the no. of pages you expected, you must create Robots txt file.
How Robots.txt File Works?
Search Engines basically do 2 following jobs:-
1. Crawling website to grab content.
2. Indexing the important pages to serve them on top of search engines.
Robots.txt File provides some commands to the search engine crawlers to crawl the web pages and grab information to index them.
The crawling of web crawlers over websites is known as ‘Spidering’. When a search engine crawler comes to crawl the website, it looks for the robots file first.

Once the crawler finds the robots file, it reads that file first to get the information, how it is supposed to crawl the website.
Robots file acts as a security agent which protects the website. It navigates the crawlers of Search Engines and directs them to different directories and pages from which the crawlers can fetch information.
Robots.txt file can block a certain post or multiple posts or the whole website from a single search engine or many search engines.
Don’t miss out :- 5 Great Search Engines: Other than Google
How do Robots.txt File Helps?
Robots.txt File helps in the following ways :-
1. It keeps the selected areas of website private.
2. Specifies the sitemaps’ location.
3. Prevents content duplicity from appearing in SERPs.
4. Preventing Search Engines to index multimedia like images and pdfs to index on website.
5. It guides the search engines which URLs the crawlers can access your site.
6. Robots.txt File specifies crawl delay to prevent servers from being overloaded when the crawler loads multiple content pieces at a single time.
Different Commands of Robots.txt file
1. User-agent Directive
It is used to specify which crawler is supposed to follow which set of rules.
For all search search engines’ crawlers we use “*” and for any specific crawler we use the name of the crawler.
The command is written as follows :-
User-agent: *
OR
User-agent: Googlebot/Yahoobot
2. Disallow Directive
This directive of Robots txt File helps to block a URL or URLs.
Following is the command for blocking URL :-
User-agent: *
Disallow: /basic-theme
This will block all URLs whose path starts with “/basic-theme”.
But it won’t block the following URL :-
http://abc.com/subtheme/basic-theme
3. Allow Directive
This is supported my many major Search Engines like Google, Yahoo, Bing, etc.
This is used to block a specific page of a directory containing many different pages.
The command is as follows :-
User-agent: *
Allow: /basic-theme/except-this-one-page
Disallow: /basic-theme/
It allows all the pages except that one mentioned page, which the developer don’t want to show.
It is further divided as :-
1. Blocking Everything
Sometimes, people create their website only for those whom they knew. They actually create their private websites.
Robots.txt File in this case uses the following command to block the entire website for all search engines :-
User-agent: *
Disallow: /
2. Allowing Everything
It means allowing all the pages of website to all the search engines.
It tells that the person that he/she is allowing all the pages to search engines’ crawlers on purpose.
The command for this is as follows :-
User-agent: *Allow:
3. Sitemap Directive
Sometimes the Robots txt File includes sitemaps directives.
Sitemap: http://abc.com/sitemap.xml
This provides the direction of Sitemap file. Sitemap is a file which contains all the URLs you want the crawler to crawl.
If your website contains XML Sitemap, you must include the directive.
How To Check If You Have Robots.txt File or Not?
If you are not sure whether you have Robots txt File or not, you can check it by using the following :-
www.yourdomainname.com/robots.txt
Simply, you have to write robots.txt after putting a slash(/) after your domain name. And if it contains robots file, it will appear.
In case, it don’t have a robots file, “no.txt” page will appear.
Conclusion
Robots.txt File is an important component of website management and Search Engine Optimization.
It plays an important role to manage the crawlers. It guides and navigates the crawlers to the URLs they are supposed to crawl and fetch the information.
It acts as a set of instruction for Search Engines’ Crawlers.
It blocks the unimportant pages or directories of a website to let the more important pages to be indexed so that the content will be prioritized.
Robots.txt File helps to prevent the crawlers crawl the low-quality or duplicate pages and hence provides them with relevant and authoritative content.
However, one cannot ignore the negative side of this file. Some Malicious Search Engines may ignore the instructions of Robots txt File. It leads to content theft and security vulnerability.
It may negatively affect the website. It will affect the ranking of website among search engines and may also impact the organic traffic at the website.

As with the advancement in technology, the Search Engines are becoming more sophisticated in ability to interpret with the JavaScript.
Robots.txt File should adapt such changes to meet the needs of these advancements. It ensures that the Search Engine Crawlers can effectively crawl the webpages and index them.
In conclusion, Robots.txt File holds a great significance in website management and in Search Engine Optimization. The ability of this file to guide and navigate the Search Engine crawlers affects the site’s visibility and performance.
It provides various benefits for Optimizing the Search Engines. Robots.txt hold a great place in this fast changing pace and continued its relevance in digital age and dynamic world.
Frequently Asked Questions (FAQs)
Q1. What is the main work of Robots.txt File?
Ans :- It blocks, allows, navigates and guides the crawlers to some specific pages of website.
Q2. What is the command for allowing all the Search Engines to Website?
Ans :- User-agent: *
Q3. How Robots file help to improve website’s ranking among Search Engine Result Pages?
Ans :- It blocks the Search Engines’ Crawlers from some unimportant pages so that it only crawls the webpages that provides useful and important information and thus index them first. It helps to enhance the visibility and performance of the website.
Q4. What is a Sitemap?
Ans :- Sitemap is a file which contains all the URLs you want the crawler to crawl.
Q5. What will be the command if I don not want to show my website to Yep Search Engine?
Ans :- User-agent: Yepbot Disallow:
Q6. What is the name of Google Crawler?
Ans :- Googlebot
Q7. What will be the command for showing single post to Bing Search Engine?
Ans :-User-agent: Bingbot Allow: /abc.com/example/
Q8. What will be the command for showing the entire website to Google Search Engine?
Ans :- User-agent: Googlebot Allow:
Q9. What will be the command for showing the entire website to Yahoo except any single post?
Ans :- User-agent: Yahoobot Disallow:/ https://abc.com/postname
Q10. What will be the command for not showing my website to any search engine?
Ans :- User-agent: *Disallow: